programmers.co.kr/learn/courses/30/lessons/77484
코딩테스트 연습 - 로또의 최고 순위와 최저 순위
로또 6/45(이하 '로또'로 표기)는 1부터 45까지의 숫자 중 6개를 찍어서 맞히는 대표적인 복권입니다. 아래는 로또의 순위를 정하는 방식입니다. 1 순위 당첨 내용 1 6개 번호가 모두 일치 2 5개 번호
programmers.co.kr
<풀이>
1. 민우의 로또 번호와, 당첨 로또 번호를 입력받는다.
2. 민우의 로또 번호가 될 수 있는 최고 순위와 최저 순위를 반환한다.
<해법>
1. 최고 순위와 최저 순위를 계산하는 방법.
=>
최고 순위 : 보이는 숫자의 맞은 갯수 + 낙서된 숫자가 다 맞은 경우
최저 순위 : 보이는 숫자만 다 맞은 경우
각각 경우에 맞게 맞은 갯수를 센 다음에 순위를 계산합니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
|
#include <iostream>
#include <string>
#include <vector>
using namespace std;
//순위 계산 함수
int ranking(int count) {
switch (count) {
case 6:
return 1;
case 5:
return 2;
case 4:
return 3;
case 3:
return 4;
case 2:
return 5;
default:
return 6;
}
}
vector<int> solution(vector<int> lottos, vector<int> win_nums) {
//선언
int hitCount, zeroCount;
vector<int> answer;
//초기화
hitCount = 0, zeroCount = 0;
/* 해법 */
//1. 맞힌 갯수와 낙서된 갯수 찾기
for (int i = 0; i < lottos.size(); i++) {
if (lottos[i] == 0) {
zeroCount++;
}
else {
for (int j = 0; j < win_nums.size(); j++) {
if (lottos[i] == win_nums[j]) {
hitCount++;
break;
}
}
}
}
//2. 최고 순위, 최저 순위 계산
int bestRank = ranking(hitCount + zeroCount);
int worstRank = ranking(hitCount);
//결과 저장
answer.push_back(bestRank);
answer.push_back(worstRank);
//결과 반환
return answer;
}
|
구현에 대해 알아볼 수 있는 문제였습니다.
'알고리즘 문제풀이 > 프로그래머스' 카테고리의 다른 글
| [C++] 프로그래머스 - 다단계 칫솔 판매 (0) | 2021.05.04 |
|---|---|
| [C++] 프로그래머스 - 행렬 테두리 회전하기 (0) | 2021.05.04 |
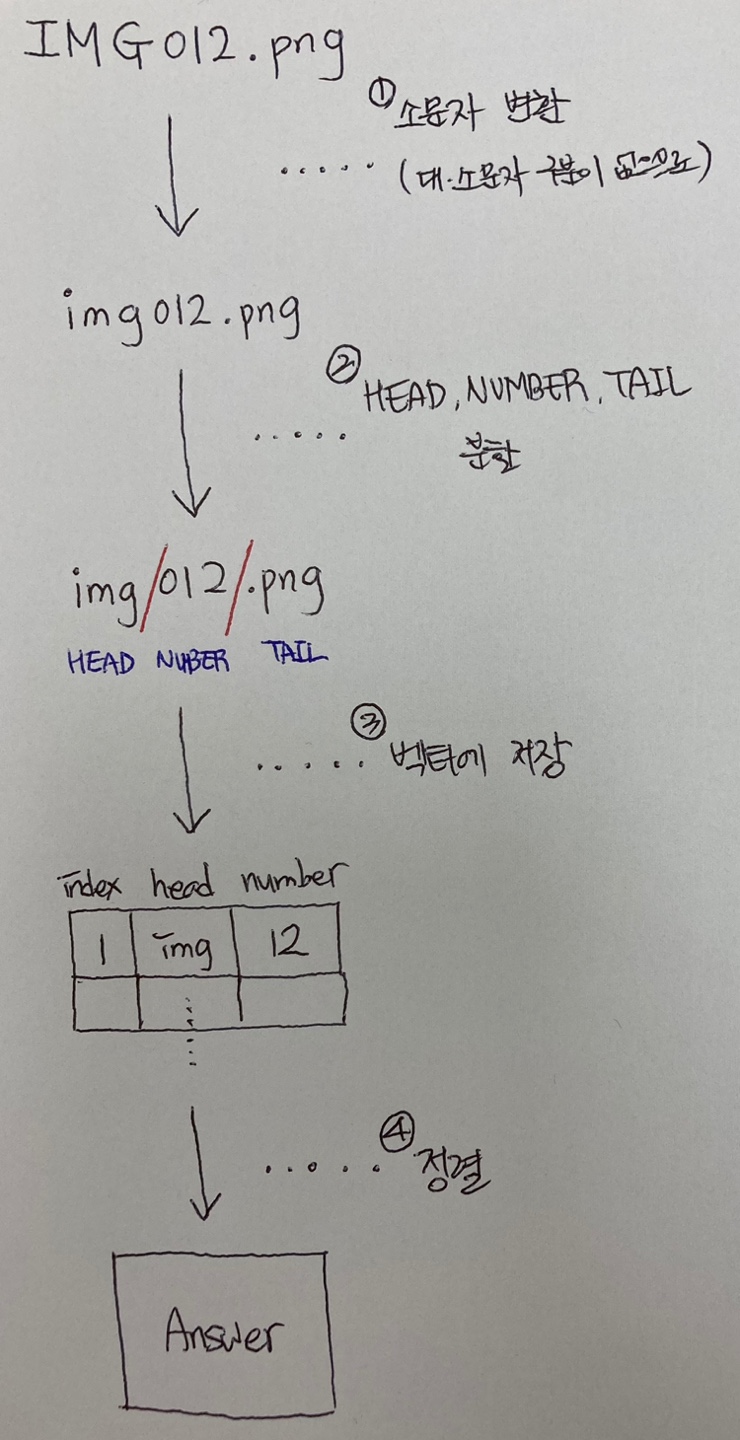
| [C++] 프로그래머스 - 파일명 정렬 (0) | 2021.04.23 |
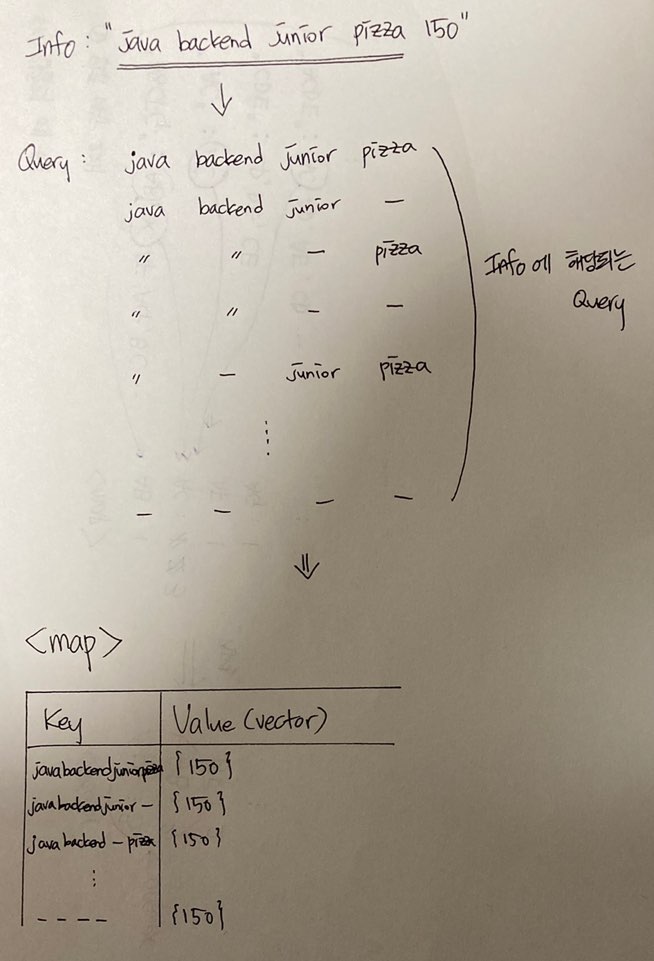
| [C++] 프로그래머스 - 순위 검색 (0) | 2021.02.02 |
| [C++] 프로그래머스 - 합승 택시 요금 (0) | 2021.01.31 |